Margins#
In this tutorial, we will:
discuss the purpose of margin cache catalogs in LSDB
Introduction#
LSDB can handle datasets larger than memory by breaking them down into smaller, spatially-connected parts and working on each part one at a time. One of the main tasks enabled by LSDB are spatial queries such as cross-matching; to ensure accurate comparisons, all nearby data points need to be loaded simultaneously. LSDB uses HATS’ method of organizing data spatially to achieve this.
However, there’s a limitation: at the boundaries of each divided section, some data points are going to be missed. This means that for operations requiring comparisons with neighboring points, such as cross-matching, the process might miss some matches for points near these boundaries because not all nearby points are included when analyzing one section at a time.
![]() Here we see an example of a boundary between HEALPix pixels, where the green points are in one partition and the red points in another. Working with one partition at a time, we would miss potential matches with points close to the boundary
Here we see an example of a boundary between HEALPix pixels, where the green points are in one partition and the red points in another. Working with one partition at a time, we would miss potential matches with points close to the boundary
To solve this, we could try to also load the neighboring partitions for each partition we crossmatch. However, this would require loading lots of unnecessary data, slowing down operations and causing issues with running out of memory. So, for each catalog, we also create a margin cache. This means that for each partition, we create a file that contains the points in the catalog within a certain distance to the pixel’s boundary.
 An example of a margin cache (orange) for the same green pixel. The margin cache for this pixel contains the points within 10 arcseconds of the boundary.
An example of a margin cache (orange) for the same green pixel. The margin cache for this pixel contains the points within 10 arcseconds of the boundary.
1. Loading Catalogs with Margins#
The easiest way to load a catalog with its margin is to use a Catalog Collection, which stores the catalog along with any supplemental catalogs such as margin caches or index catalogs in the same directory. When you open a Catalog Collection, the margin cache is automatically loaded if it is available.
Most of the catalogs on data.lsdb.io are stored as Catalog Collections, so if you’re using those catalogs, the margin cache will be loaded for you automatically.
You can check if the margin cache has been loaded by looking at the margin property of the catalog, which will show you the margin cache that has been loaded with the catalog.
Additional Help
For tips on accessing remote data, see our Accessing remote data guide
[1]:
import lsdb
ztf = lsdb.open_catalog("https://data.lsdb.io/hats/ztf_dr14", columns=["ra", "dec"])
ztf.margin
[1]:
| ra | dec | |
|---|---|---|
| npartitions=2352 | ||
| Order: 3, Pixel: 0 | double[pyarrow] | double[pyarrow] |
| ... | ... | ... |
| Order: 4, Pixel: 3070 | ... | ... |
| Order: 4, Pixel: 3071 | ... | ... |
Loading a Catalog explicitly specifying a Margin Cache#
If you’re not using a Catalog Collection, you can also specify the margin cache when opening a catalog. Margin caches are stored as separate HATS catalogs with the same partitioning as the main catalogs. To load a catalog explicitly with a margin cache, we set the margin_cache parameter with the path of the catalog’s margin catalog.
[2]:
from astropy.coordinates import SkyCoord
import astropy.units as u
from hats.pixel_math import HealpixPixel
import matplotlib.pyplot as plt
[3]:
from lsdb import BoxSearch
box = BoxSearch(ra=(179.5, 180.001), dec=(9.4, 10))
ztf_object = lsdb.open_catalog(
"https://data.lsdb.io/hats/ztf_dr14/ztf_object",
search_filter=box,
margin_cache="https://data.lsdb.io/hats/ztf_dr14/ztf_object_10arcs",
columns=["ra", "dec"],
)
print(f"Margin size: {ztf_object.margin.hc_structure.catalog_info.margin_threshold} arcsec")
ztf_object.margin
Margin size: 10.0 arcsec
[3]:
| ra | dec | |
|---|---|---|
| npartitions=4 | ||
| Order: 3, Pixel: 432 | double[pyarrow] | double[pyarrow] |
| Order: 3, Pixel: 433 | ... | ... |
| Order: 3, Pixel: 434 | ... | ... |
| Order: 3, Pixel: 435 | ... | ... |
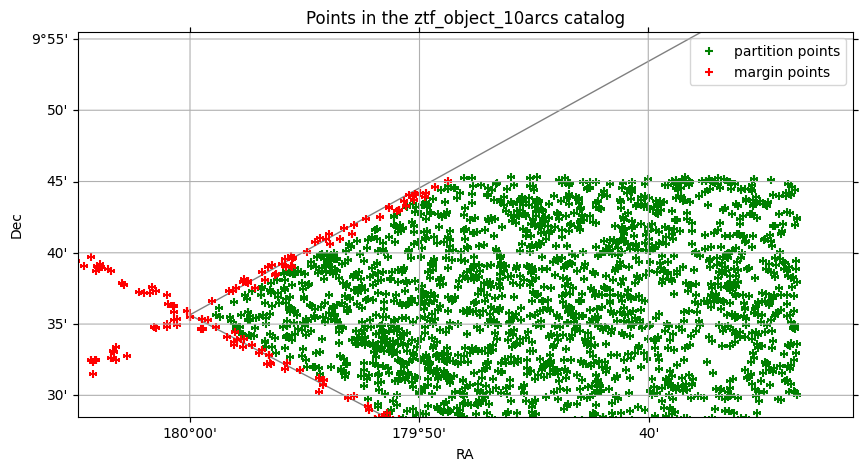
Here we see the margin catalog that has been loaded with the catalog, using a margin threshold of 10 arcseconds.
Let’s plot the catalog and its margin together:
[4]:
# the healpix pixel to plot
order = 3
pixel = 434
ztf_pixel = ztf.pixel_search([HealpixPixel(order, pixel)])
# Plot the points from the specified ztf pixel in green, and from the pixel's margin cache in red
ztf_pixel.plot_pixels(
color_by_order=False,
fc="#00000000",
ec="grey",
center=SkyCoord(179.8, 9.7, unit="deg"),
fov=(0.5 * u.deg, 0.5 * u.deg),
)
ztf_pixel.plot_points(c="green", marker="+", label="partition points")
ztf_pixel.margin.plot_points(c="red", marker="+", label="margin points")
plt.legend()
[4]:
<matplotlib.legend.Legend at 0x73283f3ea9c0>
2. Using the Margin Catalog#
Performing operations like cross-matching and joining requires a margin to be loaded in the catalog on the right side of the operation. If this right catalog has been loaded with a margin, the function will be carried out accurately using the margin, and by default will throw an error if the margin has not been set. This can be overwritten using the require_right_margin parameter, but this may cause inaccurate results!
We can see this when trying to perform a crossmatch with gaia:
[5]:
gaia = lsdb.open_catalog("s3://stpubdata/gaia/gaia_dr3/public/hats", columns=["ra", "dec"], search_filter=box)
gaia
[5]:
| ra | dec | |
|---|---|---|
| npartitions=1 | ||
| Order: 2, Pixel: 108 | double[pyarrow] | double[pyarrow] |
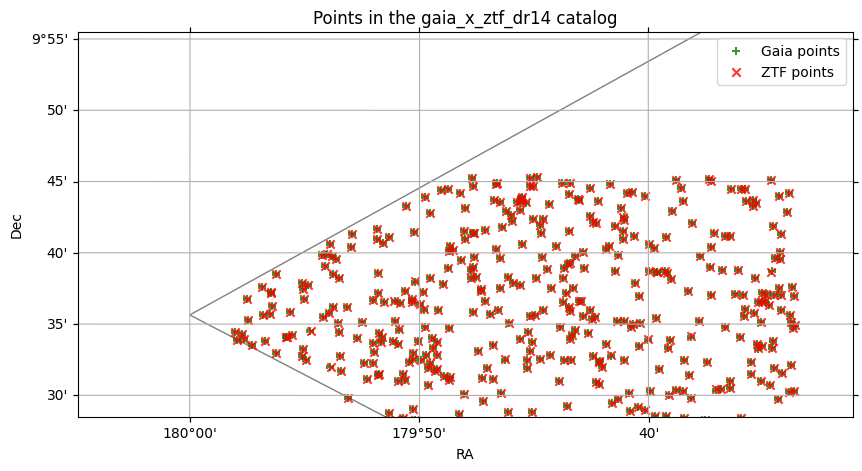
If we perform a crossmatch with gaia on the left and the ztf catalog we loaded with a margin on the right, the function works, and we get the result:
[6]:
gaia.crossmatch(ztf_object)
/home/docs/checkouts/readthedocs.org/user_builds/lsdb/envs/stable/lib/python3.12/site-packages/lsdb/catalog/catalog.py:410: FutureWarning: The default suffix behavior will change from applying suffixes to all columns to only applying suffixes to overlapping columns in a future release.To maintain the current behavior, explicitly set `suffix_method='all_columns'`. To change to the new behavior, set `suffix_method='overlapping_columns'`.
warnings.warn(
[6]:
| ra_gaia | dec_gaia | ra_ztf_dr14 | dec_ztf_dr14 | _dist_arcsec | |
|---|---|---|---|---|---|
| npartitions=4 | |||||
| Order: 3, Pixel: 432 | double[pyarrow] | double[pyarrow] | double[pyarrow] | double[pyarrow] | double[pyarrow] |
| Order: 3, Pixel: 433 | ... | ... | ... | ... | ... |
| Order: 3, Pixel: 434 | ... | ... | ... | ... | ... |
| Order: 3, Pixel: 435 | ... | ... | ... | ... | ... |
If we try the other way around, we have not loaded the right catalog (gaia) with a margin cache, and so we get an error.
[7]:
try:
ztf_object.crossmatch(gaia)
except ValueError as e:
print(f"Error: {e}")
/home/docs/checkouts/readthedocs.org/user_builds/lsdb/envs/stable/lib/python3.12/site-packages/lsdb/catalog/catalog.py:410: FutureWarning: The default suffix behavior will change from applying suffixes to all columns to only applying suffixes to overlapping columns in a future release.To maintain the current behavior, explicitly set `suffix_method='all_columns'`. To change to the new behavior, set `suffix_method='overlapping_columns'`.
warnings.warn(
We can plot the result of the crossmatch below, with the gaia objects in green and the ztf objects in red.
[8]:
order = 3
pixel = 434
crossmatch_cat = gaia.crossmatch(ztf_pixel)
ztf_pixel.plot_pixels(
color_by_order=False,
fc="#00000000",
ec="grey",
center=SkyCoord(179.8, 9.7, unit="deg"),
fov=(0.5 * u.deg, 0.5 * u.deg),
)
crossmatch_cat.plot_points(c="green", marker="+", alpha=0.8, label="Gaia points")
crossmatch_cat.plot_points(
ra_column="ra_ztf_dr14", dec_column="dec_ztf_dr14", c="red", marker="x", alpha=0.8, label="ZTF points"
)
plt.legend()
/home/docs/checkouts/readthedocs.org/user_builds/lsdb/envs/stable/lib/python3.12/site-packages/lsdb/catalog/catalog.py:410: FutureWarning: The default suffix behavior will change from applying suffixes to all columns to only applying suffixes to overlapping columns in a future release.To maintain the current behavior, explicitly set `suffix_method='all_columns'`. To change to the new behavior, set `suffix_method='overlapping_columns'`.
warnings.warn(
[8]:
<matplotlib.legend.Legend at 0x7328277def00>
3. Filtering Catalogs#
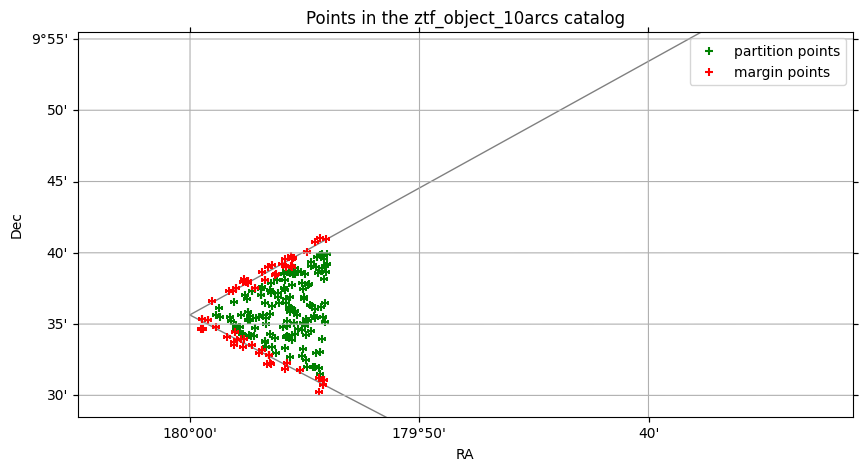
Any filtering operations applied to the catalog are also performed to the margin.
[9]:
small_sky_box_filter = ztf_pixel.box_search(ra=[179.9, 180], dec=[9.5, 9.7])
# Plot the points from the specified ztf pixel in green, and from the pixel's margin cache in red
small_sky_box_filter.plot_pixels(
color_by_order=False,
fc="#00000000",
ec="grey",
center=SkyCoord(179.8, 9.7, unit="deg"),
fov=(0.5 * u.deg, 0.5 * u.deg),
)
small_sky_box_filter.plot_points(c="green", marker="+", label="partition points")
small_sky_box_filter.margin.plot_points(c="red", marker="+", label="margin points")
plt.legend()
[9]:
<matplotlib.legend.Legend at 0x73283f1e80e0>
4. Avoiding Duplicates#
Joining the margin cache to the catalog’s data would introduce duplicate points, where points near the boundary would appear in both the margin of one partition and the main file of another partition. To avoid this, we keep two separate task graphs, one for the catalog and one for its margin.
For operations that don’t require the margin, the task graphs remain separate, and when compute is called on the catalog, only the catalog’s task graph is computed—without joining the margin or even loading the margin files.
For operations like crossmatching that require the margin, the task graphs are combined with the margin joined and used. For these operations, we use only the margin for the catalog on the right side of the operation. This means that for each left catalog point that is considered, all of the possible nearby matches in the right catalog are also loaded, so the results are kept accurate. But since there are no duplicates of the left catalog points, there are no duplicate results.
About#
Authors: Sean McGuire
Last updated on: April 18, 2025
If you use lsdb for published research, please cite following instructions.